If you’ve ever spent half an hour scrolling through a 200-page statistical plan PDF to find a clear answer, you already understand the problem.
P&C insurance carriers file statistical reports based on detailed regulatory documents called statistical plans. These plans define reporting layouts, every field, valid code, and validation rule across multiple lines of business and dozens of jurisdictions. The information is there, but the challenge is finding the right answer quickly and applying it consistently.
We built a Retrieval-Augmented Generation (RAG) system that allows subject matter experts, compliance leaders, developers, and auditors to query these plans in plain English and receive answers grounded directly in the source documents with citations to the exact pages and sections.
This isn’t a chatbot. It’s a regulatory intelligence assistant — Milton — designed for real compliance work.
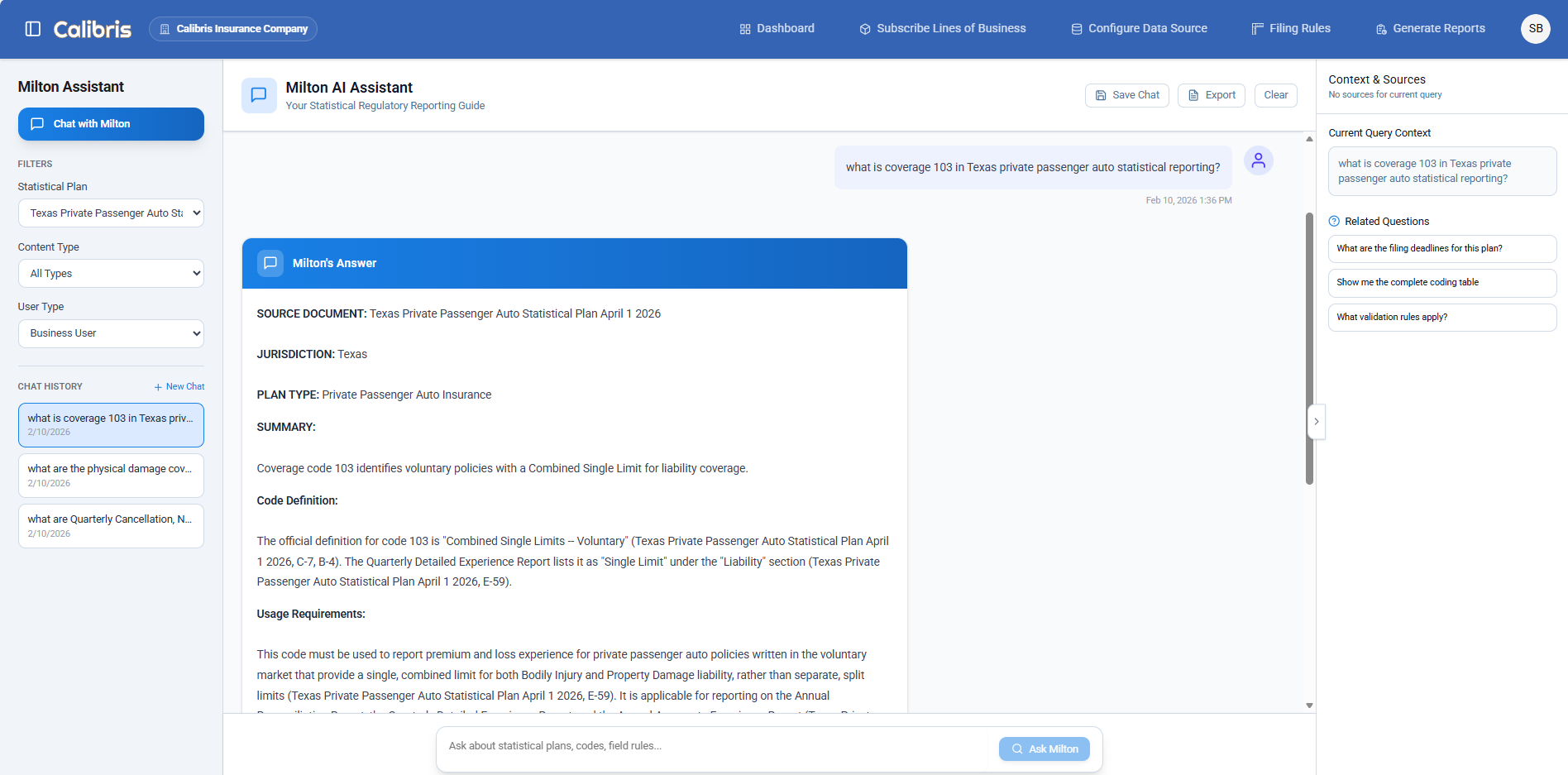
Milton answers regulatory questions with direct citations from statistical plan source text
Why Generic AI Falls Short Here
The first instinct is to upload a statistical plan into a general-purpose AI tool (ChatGPT etc.) and start asking questions. For simple lookups, that can work.
But the questions that matter in statistical reporting are rarely simple.
Ask a general model what a transaction type code means, and you’ll often get a confident answer. Sometimes it’s even correct. But ask when that code applies, or whether a field is required for a specific subline or jurisdiction, and things fall apart. The answer is usually “it depends” — on the subline, the transaction type, the jurisdiction.
In statistical reporting, context is everything. In fixed-width regulatory formats where every field position matters, there is no partial credit. Requirements vary by line, transaction type, and state.
What Actually Worked
We found that making RAG useful for regulatory work required a few practical design choices.
Preserving regulatory context before indexing. Standard document chunking strips content from its structure. A coding table pulled out of Section 4.3 loses critical meaning — you no longer know which line of business it applies to or whether it relates to premium or loss reporting. Before embedding, we enrich every chunk with its full regulatory context: section hierarchy, reporting category, and domain metadata. The system doesn’t just know what the text says; it knows “where it lives” in the regulatory structure.
That change alone reduced retrieval failures by 67% compared to basic vector search, consistent with Anthropic’s published research on contextual retrieval. In regulatory documents, context isn’t optional.
Hybrid retrieval instead of semantic search alone. Insurance documents contain both conceptual content and exact identifiers. Semantic vector search handles “What’s the difference between Coverage Code and Class Code?” well. But “What does code 611 mean?” is an exact lookup — and semantic similarity alone will not reliably find it. We run both vector search and BM25 keyword search in parallel and fuse results using Reciprocal Rank Fusion. Semantic relevance meets keyword precision. The user just asks their question.
Content-aware relevance. Not all sections of a statistical plan are equally useful for every question. Coding tables, field rules, and cross-references serve different purposes. We classify content during ingestion and adjust retrieval relevance based on both content type and query intent. That way, the right content surfaces first, not just the closest content.
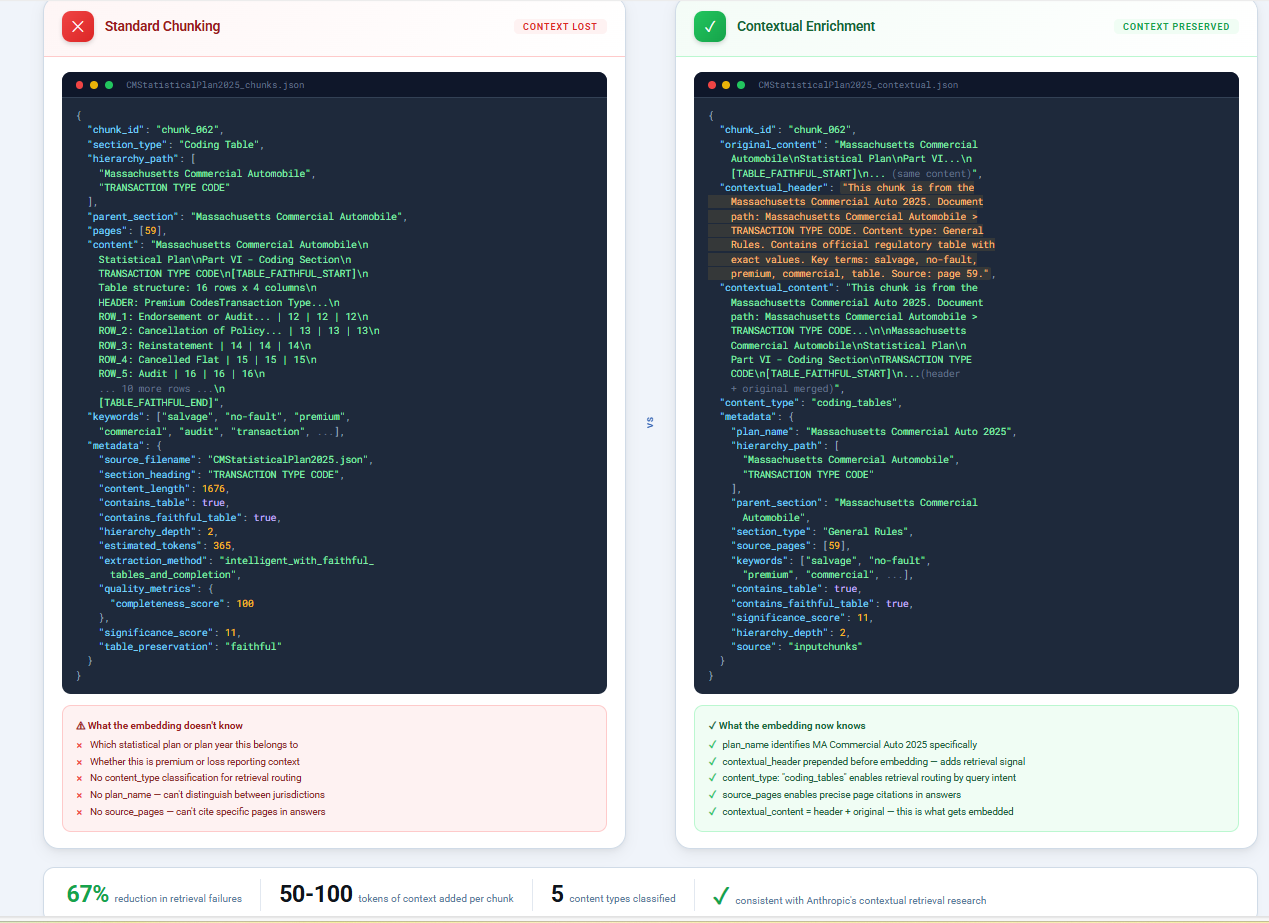
Standard chunking loses regulatory context. Contextual enrichment preserves section hierarchy and domain metadata before indexing.
The Part Most Teams Skip: Feedback and Evaluation
Every answer includes citations. Users can rate responses, flag issues, and submit corrections. Low-confidence answers are routed for domain review. Over time, this creates a growing set of verified regulatory Q&A — usable as training material, reference documentation, and ground truth for measuring system accuracy.
Compliance teams don’t trust black boxes. They shouldn’t. If you can’t trace an answer back to its source, it doesn’t belong in a compliance workflow.
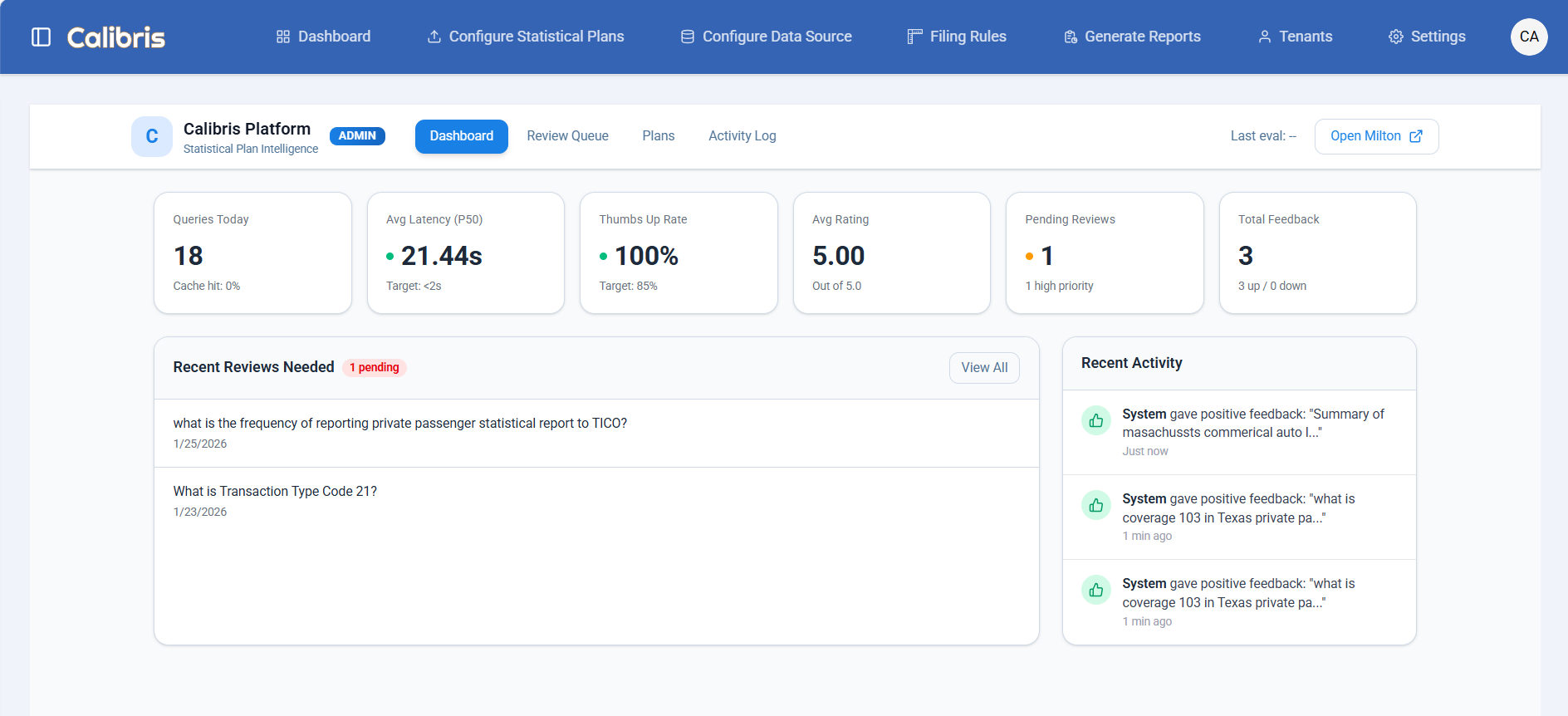
Milton’s evaluation dashboard tracks query volume, response quality, and routes low-confidence answers for expert review.
Where This Fits
This capability sits as Milton Assistant inside Calibris.ai, a self-service platform for P&C statistical reporting.
When developers configure validation rules, they can query exact regulatory requirements instead of hunting through PDFs. When compliance teams investigate a rejected filing, they get answers backed by citations — not institutional memory. The system supports multiple plans and jurisdictions, and it’s designed to evolve and improve as requirements change.
The longer-term direction is straightforward: regulatory intelligence that doesn’t just answer questions but highlights relevant changes before they become problems.
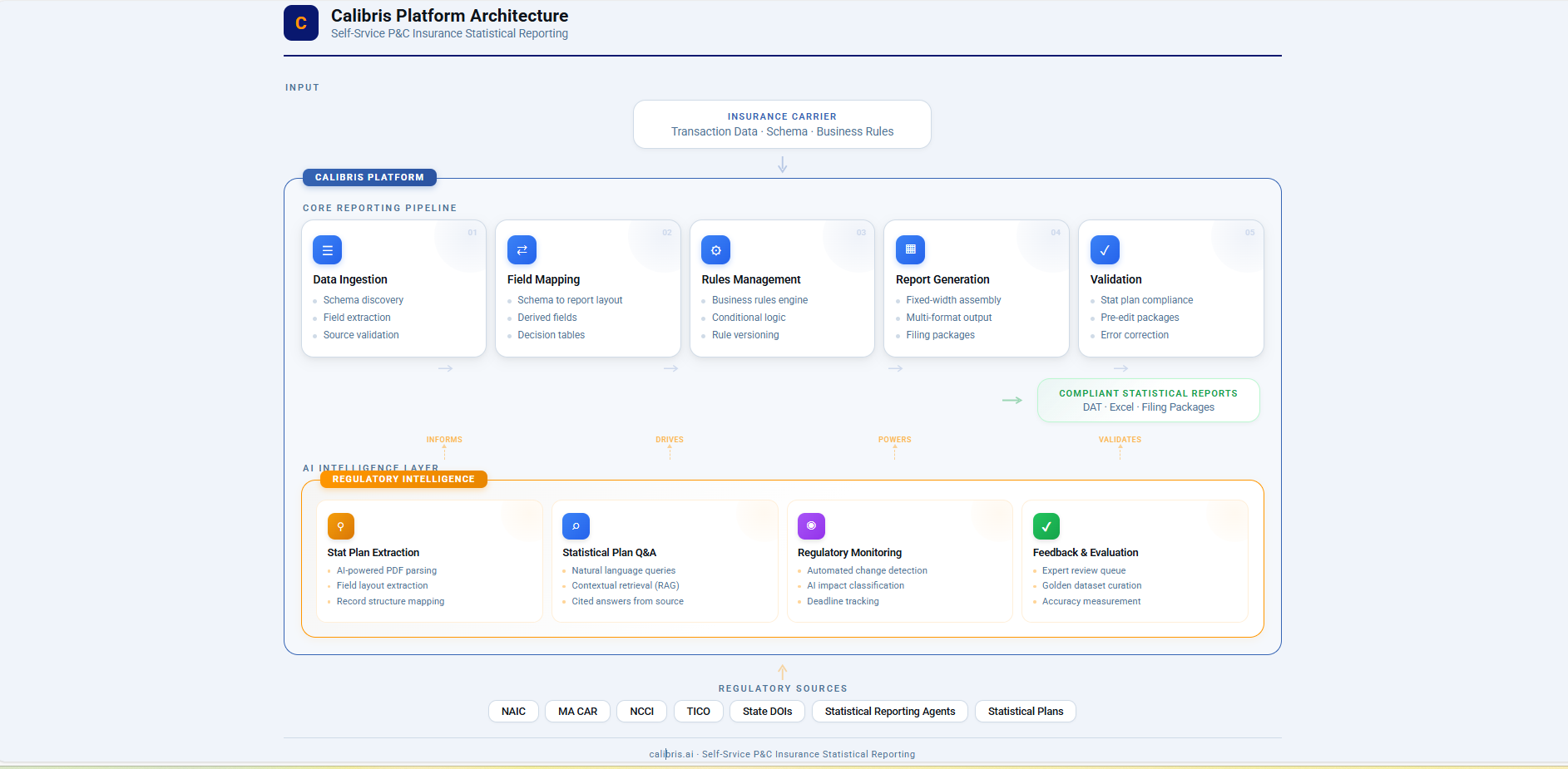
Milton’s regulatory intelligence layer powers the entire Calibris platform — from rule configuration to compliance Q&A.
This capability is evolving by design. As usage grows, Milton becomes more precise and context-aware: surfacing the rules that matter for a specific filing, not just what exists in the plan.
Insurance regulation changes constantly. The tools that support compliance need to keep up.