The hardest part of P&C statistical reporting is not generating the report. It is keeping the rules current.
Every statistical plan — MACAR, NISS, state-specific filings — defines hundreds of field-level rules: how to derive a Transaction Type Code from policy data, how to map coverage characteristics to bureau codes, how to calculate an Accounting Date from effective dates. These rules change. Statistical plans get revised. New codes appear. Existing mappings shift. And every time they do, the traditional response is the same: open a ticket, wait for a developer, schedule a release.
That cycle — business knows what changed, but engineering owns the system — is where compliance delays are born. Not because anyone is slow. Because the feedback loop has too many handoffs.
We built a system that puts rules management directly in the hands of the people who understand the rules.
The Real Bottleneck
In most statistical reporting operations, rule changes follow a familiar path:
- Compliance team identifies a change in the statistical plan
- Analyst documents the new requirement
- Developer translates the requirement into code
- Code goes through review, testing, deployment
- New rule finally reaches production — days or weeks later
This works when rules change once a year. It does not work when you are managing rules across multiple statistical plans, multiple lines of business, and multiple jurisdictions — each on their own revision schedule.
The bottleneck is not complexity. The bottleneck is access. The people who understand the regulatory requirements do not have direct access to the system that enforces them.
What Changes When Analysts Own the Rules
We built a self-service rules management interface where business analysts and compliance officers create, test, and deploy rules without writing code and without waiting for a development cycle.
Decision tables for code mappings. Most statistical reporting rules are fundamentally lookups — given these input characteristics, output this bureau code. The interface lets analysts build these as visual decision tables: define conditions using dropdowns (field, operator, value), map each combination to an output code, and see the complete mapping in a spreadsheet-like view. No SQL. No programming syntax.
Expressions for calculations. Some derived fields require computation — extracting month and year from dates, formatting accounting periods, applying modifiers. The system provides a guided expression builder with pre-built templates for common P&C calculations. Click a field name to insert it. Pick a template. Test it.
Test before you deploy. Every rule can be tested with sample data before activation. Enter a few input values, click test, see the result immediately. No staging environment. No guessing. If it works, activate it. If it doesn’t, adjust and test again.
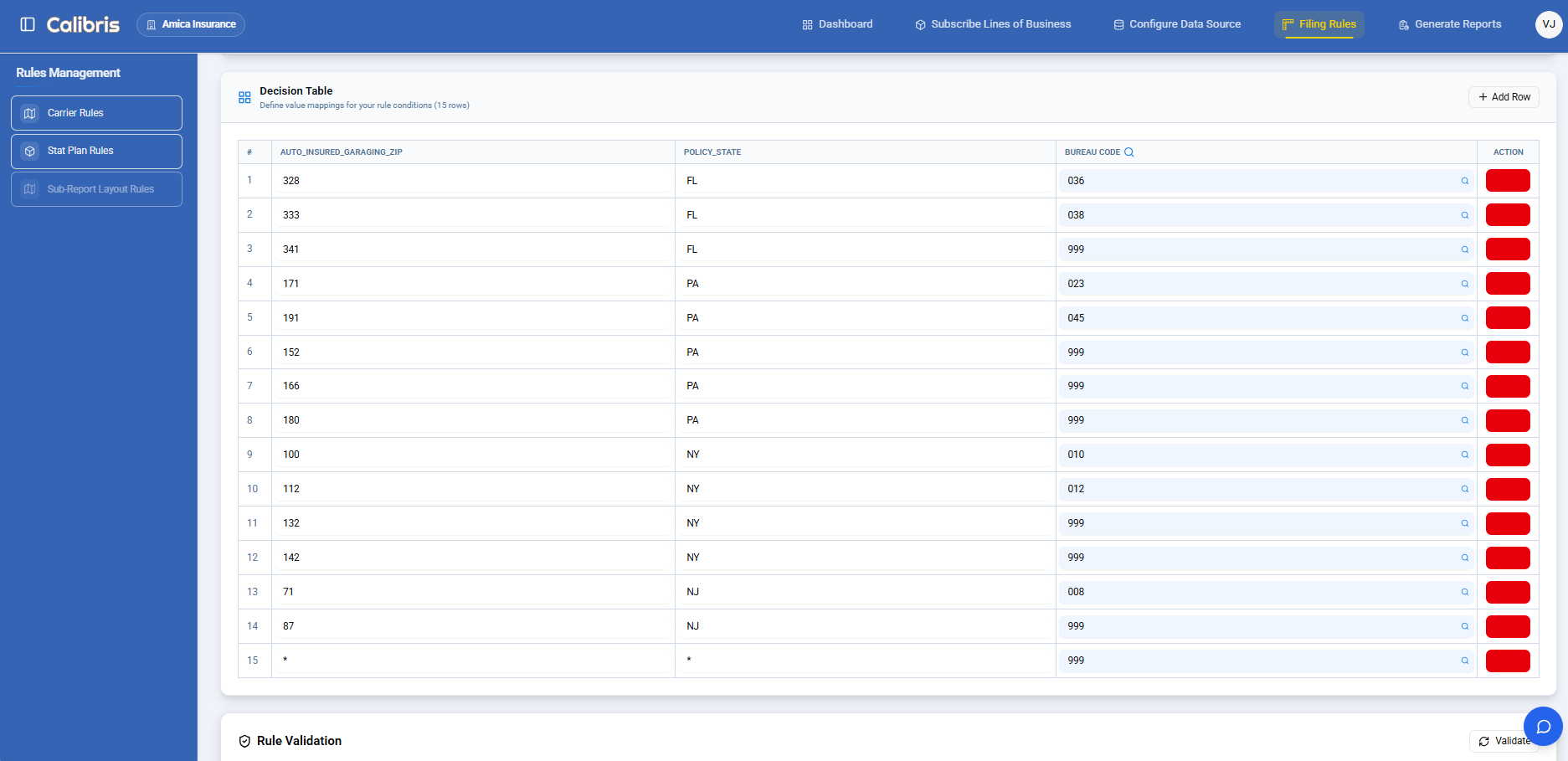
The Rule Builder interface — decision tables let analysts define condition-to-bureau-code mappings in a visual, spreadsheet-like view.
Version History and Audit Trail — Built In
In statistical reporting, knowing what a rule does is only half the requirement. Regulators and auditors want to know when it changed, who changed it, and why.
Every rule change is versioned automatically. Full timeline. Side-by-side comparison between any two versions. One-click restore if a change causes unexpected behavior. Complete audit trail — timestamp, user, action, before and after state.
This is not an afterthought bolted onto the system. It is foundational. When CAR or a state bureau asks how your Transaction Type Code mapping changed between Q1 and Q3, the answer is a click away — not a forensic investigation through git commit history that only your engineering team can perform.
Enterprise Rules Engine Under the Hood
Self-service does not mean simple underneath. The rules engine processes hundreds of thousands of records per filing cycle. Decision tables compile to optimized rule execution at scale. Expression rules execute in sandboxed environments with timeout controls and field-level dependency tracking.
The system routes rules intelligently — lightweight calculations stay fast, complex decision tables leverage an enterprise-grade rules engine optimized for high-volume pattern matching. A carrier processing 100,000+ records per filing period gets the same sub-minute execution whether the rule was built by a developer or a business analyst through the UI.
The interface is simple. The execution is not.
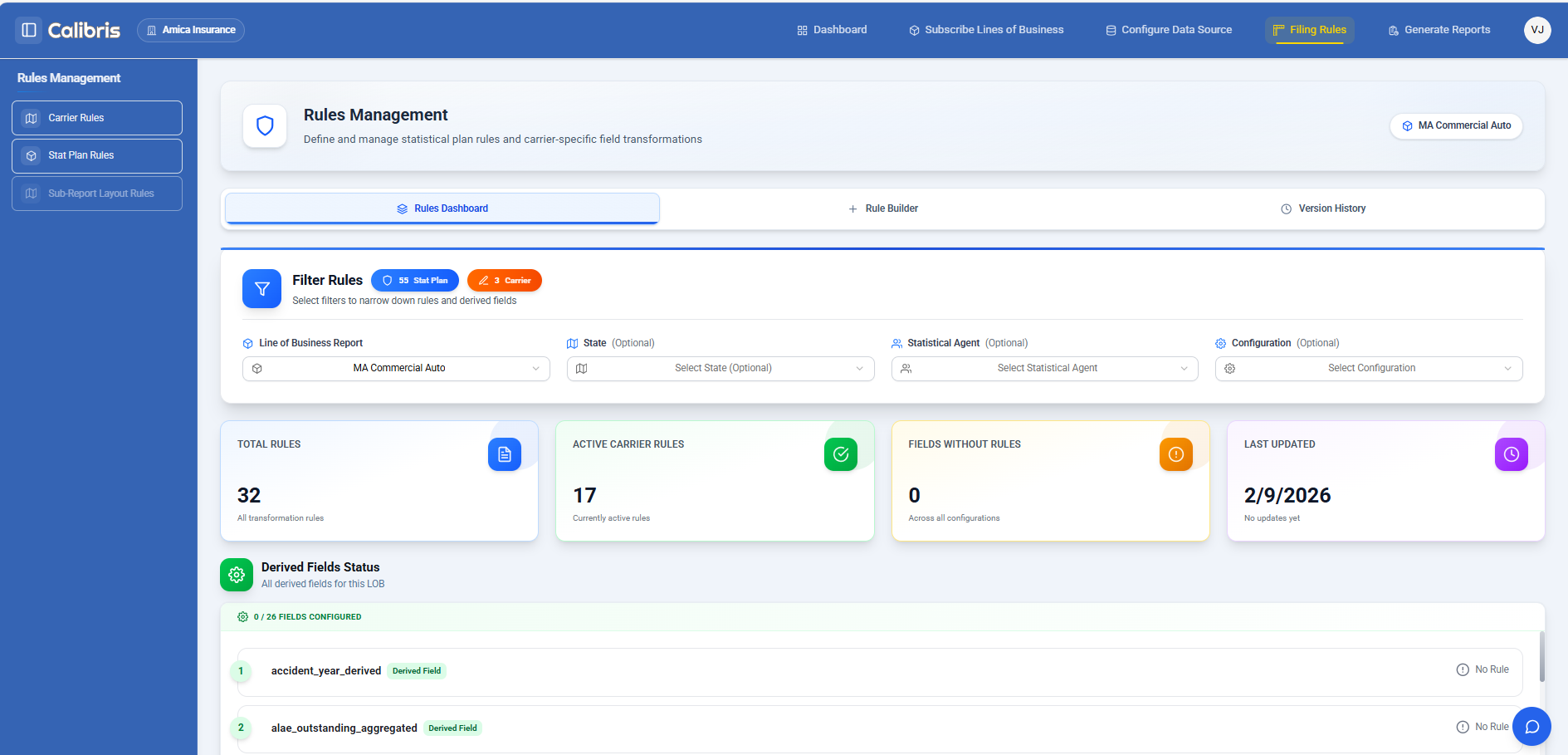
The Rules Dashboard — showing active rules, fields covered, and rule health metrics across configurations.
Why This Changes the Operating Model
This is not about saving developer time — though it does that. It is about closing the gap between regulatory knowledge and system behavior.
When a statistical plan revision changes how Coverage Codes map for a specific subline, the person who reads that circular letter can update the rule directly. Test it. Activate it. Before the next filing window — not after a failed submission reveals that the old mapping is still in place.
In traditional setups, that update touches at least three people and takes days. In this model, it takes minutes and involves the one person who actually understands the change.
Self-service without being unsafe. Real-time validation prevents incomplete or conflicting rules from being saved. Bureau code lookup ensures correct code references. Version history provides a safety net. The system moves fast because the guardrails are built into the workflow, not into a separate approval process that slows everything down.
Where This Fits
Rules management is one layer within Calibris, our platform for P&C statistical reporting automation. It connects directly to the data pipeline — when a carrier uploads raw policy or claims data, these rules transform it into bureau-ready records.
The same platform monitors regulatory changes through automated scanning of statistical plan sources, provides AI-powered intelligence for interpreting plan requirements, and generates compliant DAT files for submission.
Rules management is the operational core — where regulatory requirements become executable logic. Making that self-service is what makes the rest of the platform practical at scale.
This capability will continue to deepen as the platform matures — more rule templates, smarter conflict detection, tighter integration with regulatory monitoring so that when a statistical plan revision is detected, the affected rules surface automatically for review. The foundation is in place; the intelligence around it will keep growing.
Statistical plans will keep changing. The question is whether your rules can keep up without a development cycle every time.